テクノロジー
NPUとは何か? CPUやGPUとの違いを分かりやすく解説
はじめに
AI(人工知能)の急速な進化の背景には、膨大なデータ処理を支える半導体チップの存在があります。特にディープラーニング(深層学習)が登場して以降、従来のCPU(Central Processing Unit:中央演算処理装置)やGPU(Graphics Processing Unit:画像処理装置)に加えて、AI処理を得意とするNPU(Neural Processing Unit:ニューラルネットワークプロセッサ)が大きな注目を集めています。
本記事では、CPU、GPU、NPUの違いを「学習」(トレーニング)と「推論」(インファレンス)の観点から整理し、クラウド/PC/エッジでの活用事例やRapidusの戦略について解説します。

CPU、GPU、NPUとは何か
CPU
私たちが使っているPCやスマートフォン。その処理において中心的な役割を担うのがCPUです。CPUは多様な命令を理解し、順序立てて処理する役割を持っています。文章作成や表計算、インターネット閲覧など、一般的にコンピュータで行う動作のほとんどはCPUを通して実行されています。
CPUの大きな特徴は、汎用(はんよう)性の高さにあります。つまり、どんな種類の計算や処理に対しても対応できる万能型の存在です。しかし、同時に大量のデータを並列に処理するのはあまり得意ではなく、ディープラーニングのような大規模並列計算では効率が高いとは言えません。
CPUの進化は目覚ましく、動作クロックの向上やマルチコア化により性能は飛躍的に伸びてきました。初期のCPUは1つのコアで1つの処理を順番に行っていましたが、現在では4コア、8コアといった複数のコアを搭載するのが一般的になり、一度に並行して複数の処理を実行できるようになっています。
GPU
GPUはもともとゲームや映像編集を支える画像処理専用のチップとして開発されました。3Dグラフィックスを滑らかに描画したり美しい映像をリアルタイムに表示したりするためには、一度に大量の並列計算を実行しなければなりません。GPUは、CPUのように「順番に複雑な処理をする」のではなく、「同じ種類の計算を一気に大量に処理する」構造を採用しており、数百から数千もの小さな演算ユニットが同時に動くことが大きな特徴です。
この並列処理の仕組みがAIにおけるディープラーニングの学習と相性が非常に良いのです。AI学習は、膨大なデータを行列計算として処理しなければなりません。GPUは繰り返し計算の高速処理が得意であるため、近年はゲーム用にとどまらず、AI研究や機械学習の分野で不可欠な存在となりました。
一方、GPUの課題は消費電力と汎用性の低さです。大量のコアを高速動作させるため電力消費が大きく、特にデータセンターのように多数のGPUを使う環境では電力や熱の問題が顕在化します。また、GPUは単純な並列計算は得意ですが、分岐の多い複雑な処理は不得意なため、CPUと組み合わせて使用するのが一般的です。
NPU
NPUはAIの計算に特化した専用プロセッサです。内部構造は人間の脳の神経細胞(ニューロン)の仕組みを参考にしたニューラルネットワーク計算に最適化されており、学習済みAIモデルを使った推論処理を効率的に実行します。
CPUやGPUと大きく異なる点は「AI処理に不要な汎用回路を削ぎ落とし、AI向けの演算機能に特化している」ことです。これにより限られた電力でも高い演算性能を発揮できます。例えばNPUは4bitや8bitといった低精度計算を利用し、無駄な精度を省くことで処理効率を高めます。その結果、同じAIタスクを行う場合でもCPUやGPUより少ない電力で実行可能です。
しかし、NPUはあくまでAI用チップであるため汎用性はCPUに及びません。アルゴリズムやモデルが変化すると、それに対応する新しい設計が必要になる場合もあります。現在は、画像認識や音声認識、自然言語処理といった主要なAI分野に対応できる汎用型NPUが次々と登場しており、幅広い製品に搭載され始めています。
| 特徴 | CPU | GPU | NPU |
|---|---|---|---|
| 主な役割 | コンピュータ全体の汎用処理、司令塔 | 大規模な並列計算、グラフィック処理 | AIの推論処理に特化、省電力なAI計算 |
| 得意な処理 | ・複雑な命令の逐次処理 ・論理判断 |
・大量の単純な計算の並列処理 ・行列演算 ・3Dグラフィック描画 |
・ニューラルネットワークの推論 ・量子化された計算 |
| 強み | ・汎用性、柔軟性 ・さまざまなタスクに対応 |
・圧倒的な並列計算能力 ・大規模AI学習の高速化 |
・高い電力効率 ・エッジでのAI処理 ・特定のAIタスクに特化 |
| 弱み | ・AIの並列計算は非効率 ・大規模AI学習には不向き |
・消費電力と発熱が大きい ・小型デバイスへの搭載に限界がある |
・GPUほどの汎用性はない ・大規模AIモデルの学習には不向き ・モデルの変更に対応しにくい場合がある |
| 主な用途 | ・PCやサーバなどコンピュータのメインプロセッサ | ・AIモデルの学習 ・ゲーム、科学技術計算 |
・スマホ、スマート家電のAI機能 ・自動運転車のAI判断 ・AIカメラ、IoTデバイス |
| AI処理における役割 | ・全体統括、AI以外の汎用処理 ・AI処理の前処理、後処理 |
・AIモデルの学習 ・大規模AIの推論 |
・AIモデルの推論 ・特にエッジデバイスでの高速、省電力処理 |
| 構造の特徴 | 比較的少数の強力なコア | 多数のシンプルな計算ユニット(コア) | AI処理に特化した専用回路(アクセラレーター) |
| 処理速度 | バランス型 | 高速並列処理 | AI専用で効率的 |
| 消費電力 | 中程度 | 高い傾向 | 低く抑えられる |
AI(特にディープラーニング)の仕組みの基礎
ディープラーニングは、人間の脳の神経細胞を模したニューラルネットワークを利用する仕組みです。ニューラルネットワークは、情報を受け取る「入力層」、特徴を抽出して処理する「中間層」(隠れ層)、そして結果を出力する「出力層」という構造で成り立っています。データが層を通過するたびに特徴が強調され、最終的に答えが導かれます。
AIに関する処理は2段階に大きく分かれます。学習では、大量のデータを用いてネットワークのパラメータ(重みやバイアス)を繰り返し調整します。犬と猫の画像を分類する場合、誤差を逆方向に伝えて修正する「誤差逆伝播」という仕組みによってモデルを改善していきます。ディープラーニングの学習は、数十億ものパラメータを含む巨大なモデルを扱うことがあり、その過程で行列演算を中心とした大量の並列計算が発生します。
推論では、学習済みモデルを用いて新しいデータを入力し、新たな答えを出します。推論も一定の計算性能を必要としますが、学習に比べれば必要なリソースは少なく、スマホのようなデバイスでもリアルタイム処理が可能な場合があります。ただし画像認識や自然言語処理など複雑なモデルでは、推論でも素早く応答するために高い並列計算能力が求められます。
このように、ディープラーニングの特徴は「学習は膨大な計算と電力を必要とし、推論でも効率的な演算が欠かせない」という点にあります。
AIにはなぜ「高性能な半導体」が必要なのか
AIブームに伴って取り扱うデータ量は爆発的に増加しており、それを処理するための計算資源の重要性はかつてないほど高まっています。特にクラウドサービスの土台となる大規模データセンターでは、GPUを中心とした高性能チップが必須であり、その需要は急激に拡大しています。
生成AIの登場によって新たなサービスが次々に生まれました。これらを実現するには、膨大なデータをAIに学習させると同時に、利用時も大量の演算処理が必要です。それに伴って世界中のデータセンターの電力消費量も数倍に拡大する見通しです。
AI時代の大きな課題の一つが、この演算需要の急増と、それに直結する半導体の消費電力です。大規模なAIモデルを高速に動作させるためには、演算や冷却のために多大な電力を必要とします。最新GPUサーバ1台でさえ数キロワット規模の電力を消費し、大量の熱を発生させます。このためデータセンターでは電力供給や冷却対策が深刻な課題なのです。

こうした背景から、AIを効率的に動かすには「計算性能」と「電力効率」の両立が不可欠です。現状は、GPUがディープラーニングの中核を担っています。何千ものコアによる並列計算能力を生かし、CPUでは処理が難しい膨大な行列演算を高速に実行しているのです。
CPU、GPU、NPUの活用事例と使い分け
実際に私たちが使うデバイスやITシステムで、CPU、GPU、NPUがどのように使い分けられているかを見てみましょう。用途の代表例として、PC(パーソナルコンピュータ)、クラウドAI(データセンター)、エッジAI(デバイス)の3つの場面での活用を紹介します。
PC
日常で利用するPCでは、基本的にCPUが中心的な役割を担い、必要に応じてGPUがグラフィックス処理や高速演算を補助します。
高画質の最新ゲームや動画編集、グラフィックス作業にGPUが欠かせませんが、一般的なオフィスソフトやWebサイト閲覧といった作業の多くはCPUが中心です。
近年はこの分野にもAI活用の波が押し寄せ、NPUを搭載した「AI PC」も登場し始めました。NPUを積んだPCでは、ビデオ会議中のリアルタイムノイズキャンセル、音声の自動文字起こし、画像編集のAI補正などをクラウドに頼らずローカルで処理可能です。そのため、インターネット接続が不安定な状況でもAI機能を利用でき、さらにデータをクラウドに送らず処理できるためセキュリティ対策の強化にもつながります。
クラウドAI
検索エンジンや画像認識API、生成AIサービスなどの大規模AIは、クラウドのサーバ群で動作しています。こうした現場ではGPUを中心とした高性能チップが何百、何千と並列稼働し、膨大な計算需要に応えています。特にAIモデルの学習プロセスはクラウドのGPUサーバ群で処理されることが多く、大量の電力を消費します。
クラウドAIは性能最優先のため、高い消費電力を許容しつつも、高速化を実現するためにGPUを多数投入するアプローチが取られています。ただし、省エネは喫緊の課題であり、データセンターでもAI専用チップの導入が進んでいます。
最近はNPUや各社独自のAIアクセラレーターが使われ始め、GPUと組み合わせることで性能と省電力の両立を目指す動きが広がっています。
エッジAI
エッジAIとは、クラウドではなくスマホや家電、自動車、産業ロボットなど端末側でAI処理を行う仕組みのことです。エッジAIのメリットは、データをクラウドに送らず端末内で処理するため、低遅延で応答できるうえ、通信環境に依存しにくく、プライバシー保護にもつながる点です。
スマホに搭載されたNPUは、写真撮影後すぐに被写体を認識して最適に補正したり、音声コマンドをクラウドに送らず端末内で認識したりします。自動車では、カメラやLiDARが取得した大量のセンサーデータを車載NPUがリアルタイムで解析し、安全な走行を支えています。エッジデバイスは小型でバッテリー駆動が多いため、省電力性が非常に重要です。
GPUは高性能ですが電力消費やコストの面で組み込み用途には不向きな場合が多いため、AIアクセラレーターであるNPUが小型、低消費電力の強みを生かしてスマホやIoT機器におけるAI処理を可能にしています。
Rapidusが提唱する「専用多品種」とは〜多様化するAIのニーズ〜
AIの用途がデータセンターやスマートデバイスに広がる中、単一の汎用チップだけでは最適化が難しくなっています。Rapidusはこうした変化に対応するため、用途や顧客要件に合わせて設計を最適化し、多品種を柔軟かつ迅速に供給する「専用多品種」という製造戦略を掲げています。
このビジョンを支える取り組みの一つが、各工程を機動的に進められる「完全枚葉式プロセス」です。工程間の待ち時間や段取りロスを抑えることで、試作から量産立ち上げまでのリードタイムを大幅に短縮し、変化する市場ニーズに素早く応えることを目指しています。
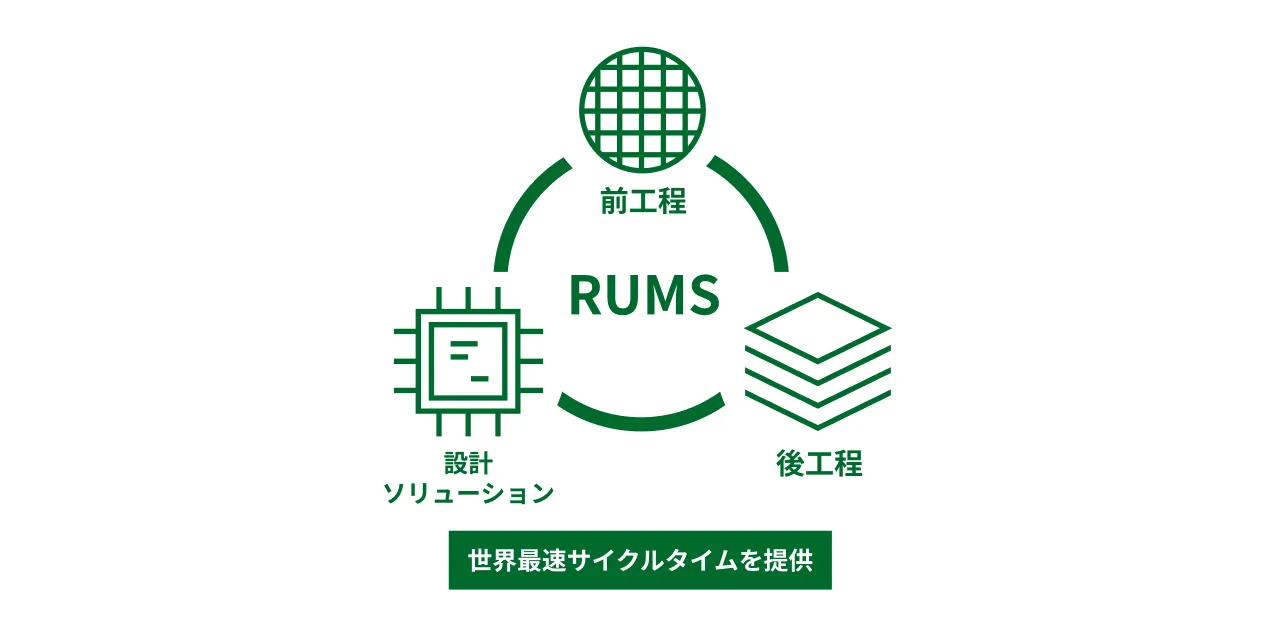
さらにRapidusはRUMS(Rapid and Unified Manufacturing Service)という新しいビジネスモデルを提唱しています。これはチップ設計支援から前工程(ウェーハ加工)、後工程(パッケージング)まで一貫して自社で行う仕組みで、顧客が求める専用チップを世界最速のサイクルタイムで届けることを目的としています。その一環として、製造時に得られる膨大なデータをAIで解析し設計に反映するDMCO(Design-Manufacturing Co-Optimization)という概念を掲げています。これはAI技術をそのまま半導体製造プロセスに生かし、歩留まりの向上や開発期間の短縮を狙う先端的な取り組みです。
まとめ
CPU、GPU、NPUそれぞれの役割と最適分野、そして最新の半導体戦略について見てきました。汎用CPUから始まったコンピュータの歴史は、GPUによる並列計算の時代を経て、今はディープラーニング隆盛の下でNPUをはじめとするドメイン特化型チップの時代へと移りつつあります。
今後AIモデルは一層高度化し、同時に省エネ性能やリアルタイム処理への要求も高まっていくでしょう。その中で半導体チップは、基盤技術としてますます不可欠な存在となります。Rapidusの挑戦に象徴されるように、必要な性能を必要な場所(クラウドやエッジ)にタイムリーに届ける技術が確立されれば、新薬の開発や気候変動の予測、個人に最適化された教育や医療サービスなど、社会を大きく変えるイノベーションが加速するはずです。
- #半導体
- #AI
- #設計
- #設計支援
おすすめ記事


