Technology
What is an NPU? Understanding the Differences Between CPUs, GPUs and NPUs
Introduction
Behind the rapid evolution of artificial intelligence (AI) lies the existence of semiconductor chips that support massive data processing. Particularly since the emergence of deep learning, neural processing units (NPU)—which excel at AI processing—have attracted significant attention alongside traditional central processing units (CPU) and graphics processing units (GPU).
In this article, we'll clarify the differences between CPUs, GPUs and NPUs from the perspectives of "training" and "inference", and explain use cases in cloud, PC and edge environments, as well as Rapidus' strategy.

What Are CPUs, GPUs and NPUs?
CPU
The PCs and smartphones we use rely on CPUs to play a central role in processing. CPUs understand diverse instructions and process them sequentially. Most common computer operations—such as writing documents, using spreadsheets, browsing the internet—are executed through the CPU.
The CPU's major characteristic is its high versatility. In other words, it's an all-purpose device that can handle any type of calculation or processing. However, it's not particularly good at processing large amounts of data in parallel simultaneously, making it inefficient for large-scale parallel computations like deep learning.
CPU evolution has been remarkable, with performance dramatically improving through higher clock speeds and multi-core architecture. Early CPUs had one core processing one task at a time sequentially, but today it's common for CPUs to have 4, 8 or more cores, enabling multiple processes to run in parallel.
GPU
GPUs were originally developed as image processing chips to support gaming and video editing. To smoothly render 3D graphics or display beautiful video in real-time requires executing massive parallel computations simultaneously. Rather than processing complex tasks sequentially like CPUs, GPUs adopt a structure that processes large quantities of the same type of calculation all at once, with a key feature being hundreds to thousands of small computing units operating simultaneously.
This parallel processing mechanism is extremely compatible with deep learning training in AI. AI training must process massive amounts of data as matrix calculations. Because GPUs excel at high-speed processing of repetitive calculations, they've become indispensable not just for gaming but also in AI research and machine learning fields in recent years.
However, GPUs face challenges with power consumption and limited versatility. Operating large numbers of cores at high speed consumes significant power, and especially in environments like data centers using many GPUs, power and heat issues become evident. Additionally, while GPUs excel at simple parallel calculations, they struggle with complex processing involving many branches, so they're typically used in combination with CPUs.
NPU
NPUs are dedicated processors specialized for AI computation. Their internal structure is optimized for neural network calculations modeled after the mechanism of neurons in the human brain, efficiently executing inference processing using trained AI models.
A major difference from CPUs and GPUs is that NPUs eliminate general-purpose circuits unnecessary for AI processing and specialize in AI-oriented computational functions. This enables high computational performance even with limited power. For example, NPUs use low-precision calculations like 4-bit or 8-bit, eliminating unnecessary precision to improve processing efficiency. As a result, they can execute the same AI tasks with less power than CPUs or GPUs.
However, because NPUs are AI-specific chips, their versatility doesn't match CPUs. When algorithms or models change, new designs may be required to accommodate them. Currently, versatile NPUs that can handle major AI fields like image recognition, voice recognition and natural language processing are emerging one after another and beginning to be incorporated into a wide range of products.
| Feature | CPU | GPU | NPU |
|---|---|---|---|
| Primary Role | General-purpose processing for entire computer, command center | Large-scale parallel computation, graphics processing | Specialized in AI inference, power-efficient AI computation |
| Specialized Processing |
• Sequential processing of complex instructions • Logical decisions |
• Parallel processing of massive simple calculations • Matrix operations • 3D graphics rendering |
• Neural network inference • Quantized calculations |
| Strengths |
• Versatility, flexibility • Handles various tasks |
• Overwhelming parallel computing capability • Accelerates large-scale AI training |
• High power efficiency • AI processing at the edge • Specialization in specific AI tasks |
| Weaknesses |
• Inefficient for AI parallel computation • Unsuitable for large-scale AI training |
• High power consumption and heat generation • Limited capability for small device integration |
• Less versatile than GPUs • Unsuitable for large-scale AI model training • May struggle adapting to model changes |
| Main Applications | • Main processor for PCs, servers, and computers |
• AI model training • Gaming, scientific computing |
• AI features in smartphones, smart home appliances • AI decision-making in autonomous vehicles • AI cameras, IoT devices |
| Role in AI Processing |
• Overall coordination, general-purpose non-AI processing • Pre-processing and post-processing for AI |
• AI model training • Large-scale AI inference |
• AI model inference • Especially high-speed, power-efficient processing on edge devices |
| Structural Features | Relatively few powerful cores | Many simple computing units (cores) | Dedicated circuits specialized for AI processing (accelerators) |
| Processing Speed | Balanced | High-speed parallel processing | Efficient for AI-specific tasks |
| Power Consumption | Moderate | Tends to be high | Kept low |
Fundamentals of AI and Deep Learning Mechanisms
Deep learning uses neural networks modeled after human brain neurons. Neural networks consist of an input layer that receives information, hidden layers (intermediate layers) that extract and process features and an output layer that produces results. As data passes through layers, features are emphasized, ultimately deriving an answer.
AI-related processing is broadly divided into two stages. In training, network parameters (weights and biases) are repeatedly adjusted using large amounts of data. When classifying dog and cat images, for example, a mechanism called backpropagation propagates errors backward to make corrections, improving the model. Deep learning training can handle huge models containing billions of parameters, generating massive parallel computations primarily involving matrix operations.
In inference, trained models use new input data to produce new answers. While inference requires certain computational performance, it needs fewer resources than training, making real-time processing possible even on devices like smartphones in some cases. However, for complex models like image recognition or natural language processing, high parallel computing capability is required for inference to respond quickly.
Thus, deep learning's characteristics are that training requires enormous computation and power, while efficient operations are also essential for inference.
Why Does AI Need High-Performance Semiconductors?
With the AI boom, the volume of data being handled has exploded, and the importance of computational resources to process it has become unprecedented. Especially in large-scale data centers that form the foundation of cloud services, high-performance chips centered on GPUs are essential, and demand is rapidly expanding.
The emergence of generative AI has spawned new services one after another. Realizing these requires training AI on massive datasets while also requiring enormous computational processing during use. Correspondingly, global data center power consumption is projected to expand several-fold.
One major challenge in the AI era is this surge in computational demand and the directly related semiconductor power consumption. Operating large-scale AI models at high speed requires tremendous power for computation and cooling. Even a single latest GPU server consumes kilowatts of power and generates massive heat. This makes power supply and cooling measures serious challenges for data centers.

Against this background, efficiently operating AI requires balancing both computational performance and power efficiency. Currently, GPUs play the central role in deep learning. Leveraging parallel computing capability from thousands of cores, they execute at high speed the massive matrix operations that are difficult for CPUs to process.
Use Cases and Differentiation of CPUs, GPUs and NPUs
Let's look at how CPUs, GPUs and NPUs are differentiated in the devices and IT systems we use. As representative examples of applications, we'll introduce their use in three scenarios: PCs, cloud AI data centers and edge AI devices.
PC
In everyday PCs, CPUs fundamentally play the central role, with GPUs assisting with graphics processing and high-speed computation as needed.
GPUs are essential for high-quality modern gaming, video editing and graphics work, but CPUs handle most tasks like typical office software and web browsing.
Recently, the wave of AI utilization has reached this field too, with AI PCs equipped with NPUs beginning to emerge. PCs with NPUs can process real-time noise cancellation during video conferences, automatic voice transcription and AI-powered image editing corrections locally without relying on the cloud. Therefore, AI functions can be used even when internet connectivity is unstable, and because data can be processed without sending to the cloud, security measures are also strengthened.
Cloud AI Data Centers
Large-scale AI like search engines, image recognition APIs and generative AI services operate on cloud server clusters. In these environments, hundreds or thousands of high-performance chips centered on GPUs operate in parallel to meet enormous computational demand. Particularly, AI model training processes are often handled by cloud GPU server clusters, consuming large amounts of power.
Cloud AI data centers prioritizes performance, taking an approach of deploying many GPUs to achieve speed while tolerating high power consumption. However, energy efficiency is an urgent challenge, and AI-dedicated chip adoption is progressing even in data centers.
Recently, NPUs and each company's proprietary AI accelerators are beginning to be used, and movements are spreading to balance performance and power efficiency by combining them with GPUs.
Edge AI Devices
Edge AI refers to a mechanism where AI processing occurs on device side—smartphones, home appliances, automobiles and industrial robots—rather than in the cloud. Edge AI's benefits are that by processing data within devices, without sending to the cloud, it can respond with low latency, is less dependent on communication environment and also contributes to privacy protection.
NPUs embedded in smartphones immediately recognize subjects after photo capture for optimal correction or recognize voice commands within the device without sending to the cloud. In automobiles, onboard NPUs analyze in real-time the large amounts of sensor data acquired by cameras and LiDAR, supporting safe driving. Because edge devices are small and often battery-powered, power efficiency is extremely important.
While GPUs are high-performance, they're often unsuitable for embedded applications in terms of power consumption and cost, so NPUs—as AI accelerators—leverage their compact, low-power strengths to enable AI processing in smartphones and IoT devices.
Rapidus' Customized High-Mix Concept: Diversifying AI Needs
As AI applications expand to data centers and smart devices, optimization with a single general-purpose chip alone is becoming difficult. To respond to these changes, Rapidus advocates a manufacturing strategy called customized high-mix, which optimizes designs according to applications and customer requirements while flexibly and quickly supplying diverse products.
One initiative supporting this vision is the fully single-wafer process that enables agile progress through each process. By suppressing waiting time between processes and setup losses, the aim is to dramatically shorten lead time from prototyping to mass production startup, quickly responding to changing market needs.
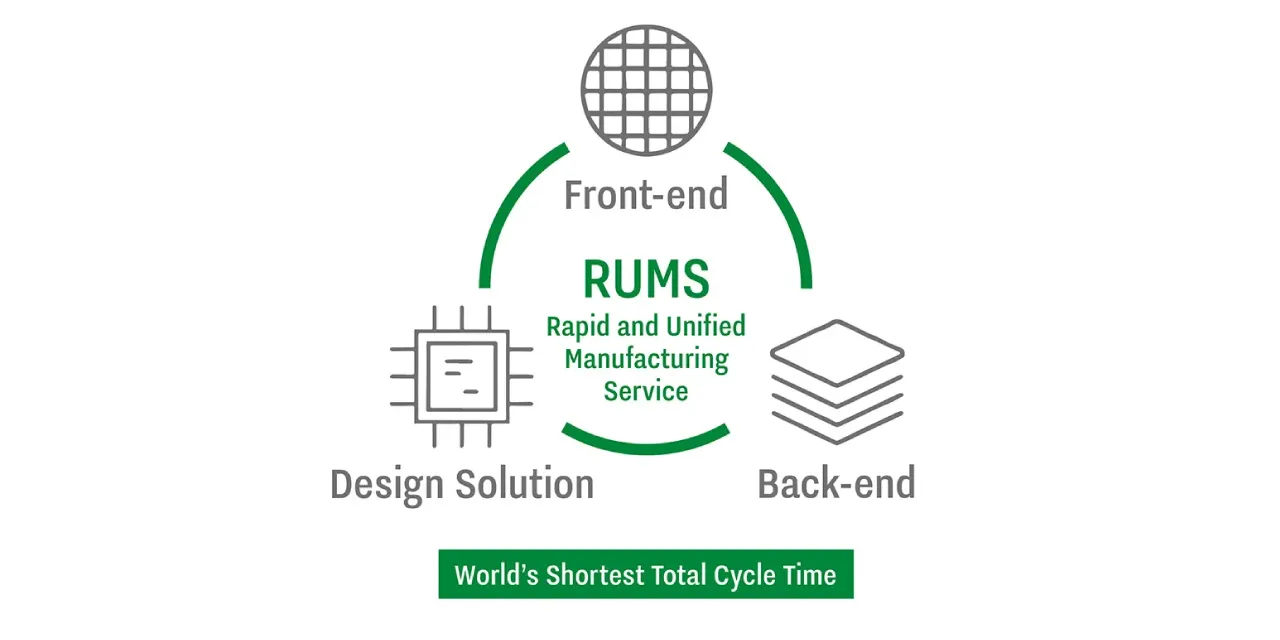
Furthermore, Rapidus has developed a new business model called Rapid and Unified Manufacturing Service (RUMS). This is an approach where everything from chip design support through front-end processes (wafer processing) to back-end processes (packaging) is handled in-house, with the purpose of delivering custom chips customers require in the world's fastest cycle time. As part of this, the company also pioneered a concept called Design-Manufacturing Co-Optimization (DMCO), which analyzes massive data obtained during manufacturing with AI and reflects it in design. This is a cutting-edge initiative that directly applies AI technology to semiconductor manufacturing processes, aiming to improve yield and shorten development periods.
Conclusion
We've examined the respective roles and optimal fields of CPUs, GPUs and NPUs, as well as the latest semiconductor strategies. Computer history, which began with general-purpose CPUs, passed through the era of parallel computation with GPUs, and is now shifting to an era of domain-specific chips like NPUs under the flourishing of deep learning.
Moving forward, AI models will become even more sophisticated, while simultaneously demands for energy-efficient performance and real-time processing will increase. Amid this, semiconductor will become increasingly indispensable as foundational technology. As symbolized by Rapidus' challenge, if technology is established that delivers required performance to required locations (cloud or edge) in a timely manner, innovations that will dramatically change society—such as new drug development, climate change prediction and education and medical services optimized for individuals—should accelerate.
- #Semiconductor
- #AI
- #Design
- #Design Solution
Recommendation


